tags: aquilenet oups¶
 Ateliers d'Admins Aquilenet - Session mai 2026¶
Ateliers d'Admins Aquilenet - Session mai 2026¶
https://blabla.aquilenet.fr/b/sam-d72-pkf-qzi
Andreas m'a demandé si j'étais dispo pendant le long week-end du 14-17 mai (week-end de l'Ascension), il a un camarade de Guix qui passe sur Bordeaux pour changer les disques de leur machine hébergée à Cogent. Puisque leur changement de disque équivaut à une réinstallation complète de la machine, Andreas pensait sortir la machine du DC, la reconfigurer tranquillement chez lui et retourner au DC pour la réinstaller. Aquilenet a aussi quelques opérations à faire à Cogent, notamment changer les PDUs et sans doute encore changer un disque tant qu'on y est, donc on pourrait en profiter (en plus, la machine Guix n'a pas d'alimentation redondée, ça semble donc une bonne idée de toucher au PDU pendant que la machine n'est pas en fonction :) ). En plus de ça, on a encore plein de tâches d'admin (mises à jour des services, upgrade en Trixie, configuration de charon22, changement de cerbere11, industrialisation du Proxmox, ...), donc ça peut être l'occasion de se faire une session d'admin à la mezzanine.
Proposition de programme¶
- Jeudi
- 10h : préparation du PDU
- 12h : miam
- 14h : passage au Cogent : changement PDU, changement disque de Chloris, démontage de Guix
- Retour à la mezz : tout le reste
- Vendredi
- Tout le reste
- Samedi / Dimanche
- Retour au Cogent pour remettre Guix
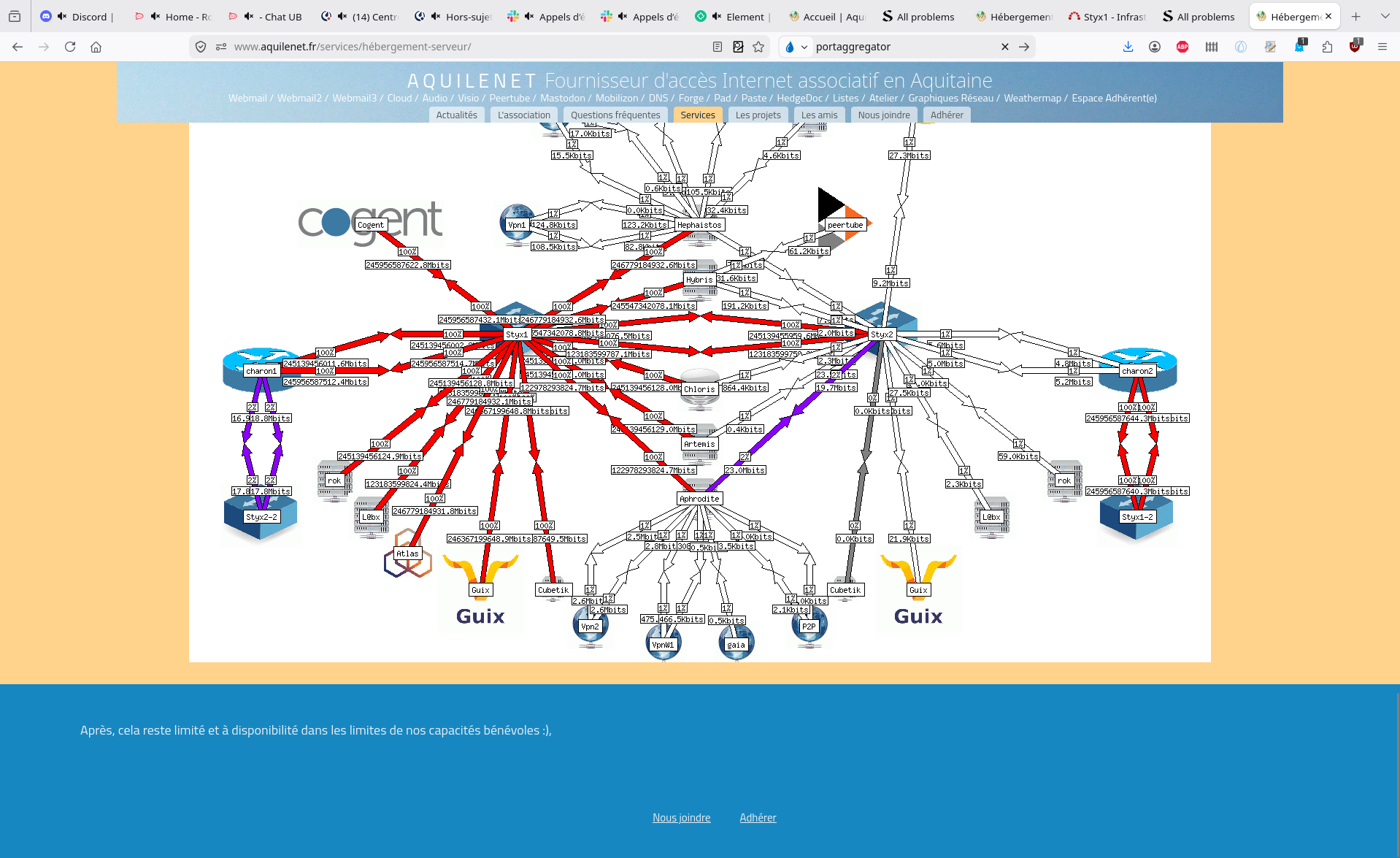
Passage Cogent¶
Refait des branchements électriques pour éviter d'avoir les deux alims d'un même serveur sur une même multiprise. Complété le netbox, il ne manque plus grand chose.
Au rebranchement, l'alim de gauche d'Artemis ne se rallume pas, on a donc perdu la redondance pour elle. On a sorti l'alim, elle est sur une table pas loin de l'imprimante.
Par ailleurs, la fibre d'arrivée Cogent a réduit sa synchronisation à 1Gbps, c'est assez incompréhensible puisqu'on n'a pas touché à la partie haute de la baie. Rebooter le styx1 n'a pas résolu le problème, ça a fait un joli arbre de noël par contre :)
Mais on a remarqué que si on perd la connexion avec Cogent, la connexion via Ielo/Paris ne permet pas de garder une connectivité avec Paris (pourquoi ?)
changé un vieux disque d'aphrodite
Configuration et changement du PDU pilotable¶
Le PDU pilotable est le ATEN PE6208. Il lui manque une patte de fixation... Il récupère son adresse IP en DHCP (adresse MAC : 00:10:74:9D:8C:8D). On a configuré le serveur DHCP de Cogent pour lui attribuer une adresse IP fixe 10.10.10.246/24
telnet <ip> # passer off : sw o01 imme off # passer on : sw o01 imme on read status o01 read meter dev curr > read meter dev curr C:0.00 > read meter dev volt V:236.72 > read meter dev pow POW:0.0000 > read meter dev pd PD:4160.2988 > read meter dev pf Not Support > read meter dev freq FREQ:50.00
Documentations :
- https://atelier.aquilenet.fr/projects/infrastructure/wiki/IPMI#PDU-ATEN-6208G
- https://netbox.aquilenet.fr/dcim/devices/52/
Pour le PDU EATON (non pilotable), qui reste à la mezzanine pour l'instant :
- https://netbox.aquilenet.fr/dcim/devices/53/
- https://atelier.aquilenet.fr/projects/infrastructure/wiki/IPMI#PDU-EATON-ePDU-G3-EMIH28
Échec de l'installation à Cogent du PDU : les pattes ne permettent pas de le fixer
On a amputé un switch cisco d'une patte, tapé sur son ergot pour qu'il ne gêne pas
installé à Cogent, il manquait un bout de config dhcp, après correction il a bien pris l'ip 10.10.10.246
Changer disque hdc de chloris¶
done, resilvering, ETA vers 22h, done
Mettre à jour Chloris vers Trixie¶
Vérifier ZFS https://tracker.debian.org/pkg/zfs-linux : rien de particulier a priori
Attendre que le resilver soit terminé, done
En cours vers deb12, pas de difficulité. Mais la mise à jour de zfs provoque un resilver
Le redémarrage du serveur montre que sdc1 est faulted, a priori c'est parce qu'on l'avait donné sous la forme /dev/sdc et que l'ordre des disques peut changer
-> re-ajouté au zfs avec /dev/disk/by-id, ça resilver
Tunnel avec BGP pour sasu.pakao.it.services¶
BGP charon22 <> charon{1,2}¶
Fait :white_check_mark:
Mise en place d'IP en /31 entre charon22 et charon{1,2}
Ajout des sondes Nagios pour les sessions BGP correspondantes
Réparation des sondes Nagions BGP sur charon{1,2}
Redondance L2TP¶
l2tpns configuré et lancé sur charon22
Il y a un problème de multicast sur le vlan501, qui empêche charon21 de savoir que charon22 est là. charon22 par contre voit bien les sessions de charon21.
Du coup, il ne faut pas terminer le service l2tpns sur charon21 sinon il va tuer toutes les sessions.
Si charon21 disparait brutalement, charon22 pourra par contre reprendre la main immédiatement avec toutes les sessions Netwo actives.
Tunnel et redondance charon22 <> cerbere11¶
Ptet attendre cerbere12/13 ?
styx11 / 12¶
Configuré le port 41 pour cerbere12
ajouté des vlan 13 et 14 pour porter les collectes axione et kosc
augmenté la system mtu à 1998, le max sans utiliser des jumboframes
ajouté les IPs 81 et 82 pour la redondance FTTH entre cerbere12 et cerbere13
pour faire de la place:
- styx12: débranché 35 - 36 qui ne sont pas configurés dessus (ancien paquerette ?)
- styx11: débranché 38 qui est configuré mais off (spa112)
Exposé les collectes Axione et Kosc aux deux cerbere12 et 13 sur les em0 et em1, comme sur cerbere11
cerbere12 et 13¶
cassou et youpi sont dessus, Sacha est arrivé en renfort
- cerbere13
- mise à jour vers OpenBSD 7.8 faite
- cerbere12
- installation OpenBSD 7.8 : galère à distance, réglé en local. cerbere12 est maintenant à jour également.
- interversion des adresses des vlans : on affecte les *.252 à cerbere12 et les *.253 à cerbere13
Ajouté une deuxième session sur axione et sur kosc pour cerbere13, avec les ips 46.231.240.81 et 46.231.240.82
Ajouté des gre entre charon21 et cerbere13
Ajouté un pfsync entre les openbsd sur le vlan20
Ajouté des carp sur tous les vlans, priorisés sur cerbere13, pour avoir les perfs
Ajouté un ospf sur cerbere13.
Ça a l'air de fonctionner !
Reste à vérifier que rien ne casse en enlevant cerbere11
Et ensuite on peut configurer cerbere12 comme cerbere13, en redondance
Guix¶
Ils ont réinstallé sur un nouveau disque, ont ajouté des disques.
Des difficultés à sortir/rentrer le serveur, des bouts d'acier et des vis dépassent un peu... Ça finit par rentrer...
Mise à jour des machines et services compliqués¶
- vers 12 :
- vers 13 :
ansible-playbook playbooks/debian_version.yml -i aquilinventaire_machines_sensibles.yml -i aquilinventaire_machines_classiques.yml | grep "item="
| Fait | Machine | Version actuelle | Commentaire |
|---|---|---|---|
| 12 | chloris | 11 | NFS, attention à ZFS, et autant attendre le resilver complete |
| cresus | 11 | dolibarr, à mettre à jour à >= 19 d'abord, pour supporter php8.2 de debian 12 et >= 21 pour supporter php8.4 de debian 13 ( https://wiki.dolibarr.org/index.php/Versions ), sans doute qu'on la laisse à Samuel :) | |
| 12 | hestia | 11 | www.aquilenet.fr, attention à ce que le site continue à fonctionner (cf en dessous) |
| enyo | 11 | Redmine, mettre d'abord à jour Redmine | |
| echo | 20.04 | Ubuntu, BigBlueButton, sans doute plus facile de créer une nouvelle VM | |
| X | aphrodite | 12.13 | hyperviseur Xen |
| En cours | hades | 12.13 | webmail2, ns secondaire ... |
| X | hephaistos | 12.13 | hyperviseur Xen |
| hera | 12.13 | LDAP et mail, essayer hades d'abord | |
| X | hybris | 12.13 | hyperviseur Xen |
| hypnos | 12.13 | Wireguard primaire, d'abord passer à bird2 (cf thanatos) | |
| alcyon | 12.13 | Mastodon, on leur laisse :) | |
| X | angelie | 12.13 | Sympa |
| argos | 12.13 | Peertube | |
| athena | 12.13 | Supervision+weathermap, utilise python2, ça peut être plus simple de faire une nouvelle VM avec nagios en réutilisant notre config presque telle quelle | |
| dionysos | 12.13 | Nextcloud et sites perso | |
| gaia | 12.13 | Beaucoup de choses, essayer hades d'abord pour la partie NS et webmail | |
| metis | 12.13 | Zammad, https://zammad.com/en/product/releases/7-0 | |
| X | palamede | 12.13 | Collabora |
| X | seraphin | 12.13 | Prometheus et Grafana |
| X | sisyphe | 12.13 | Etherpad et HedgeDoc |
| X | talos | 12.13 | CI |
- Mise à jour de talos et angelie en 13 :white_check_mark:
- Mise à jour de hestia vers 12, mais le site est toujours en Python 2.7. Il a fallu adapter la configuration de gunicorn pour qu'il écoute sur une IP plutôt sur un fichier socket
- :warning: il faut mettre à jour le site vers Python 3 avant de passer à Debian 13 : actuellement gunicorn tourne avec python2.7, qui est installé, mais plus disponible dans aucun dépôt
- il faudrait tester que le site continue à fonctionner avec un gunicorn lancé avec un python3
- tant qu'à faire, il faut changer l'environnement virtuel Python depuis lequel est lancé gunicorn pour utiliser un environnement virtuel Python (à créer avec
python3 -m venv venv, par exemple) - cf https://atelier.aquilenet.fr/projects/infrastructure/wiki/Web#Fonctionnement-en-production
- Mise à jour de seraphin en 13 :white_check_mark:
- Mise à jour de palamede en 13 :white_check_mark:
- Mise à jour de sisyphe en 13, reste /etc/redis/redis.conf et /etc/mysql/mariadb.conf.d/50-server.cnf qui sont ceux d'origines (redis.conf.dpkg-new et 50-server.cnf.dpkg-new à adapter).
- Mise à jour d'hades en 13. config dovecot à adapter cf https://doc.dovecot.org/2.4.4/installation/upgrade/2.3-to-2.4.html, fait pour local.conf. postfix à pas l'air ok, /etc/postfix/main.cf.proto et master.cf.proto concervés mais probablement à adapter (voir les versions .dpkg-dist). webmail2 nécéssitait de changer include conf-available/php8.2-fpm.conf en 8.4 ;)
- Redmine :
- Mise à jour de Chloris vers 12 faite, pas de difficulté. La mise à jour de zfs provoque un resilver. On va attendre qu'il termine pour passer en 13
- Mise à jour de aphrodite vers 13 :
- pas de réseau au redémarrage (de façon plus ou moins aléatoire), il fallait
ifdown enps...etifuppour que ça revienne, on pourrait avoir besoin de le passer en mode active-backup - kreboot ne fonctionne toujours pas.
- on a créé un service SystemD pour hp-health, pour que la sonde Nagios Power continue de fonctionner (
/opt/check_power).
- pas de réseau au redémarrage (de façon plus ou moins aléatoire), il fallait
- Mise à jour de hephaistos vers 13 : mêmes problèmes que aphrodite, passé en mode active-backup car pas réussi à faire tomber le lacp en marche.
- Mise à jour de hybris vers 13 : ràs
- Mise à jour de hades: pas facile entre slapd, dovecot, postfix, et le webmail. dovecot et postfix ont pas mal changé, il faut reprendre ça au calme avant de passer à hera.
Fournir un Wireguard à un adhérent¶
https://aide.aquilenet.fr/#ticket/zoom/5197
https://atelier.aquilenet.fr/projects/aquilenet/wiki/Wireguard